在面包店购买面包的真实经历使我发现,面包店内排队缴费的队伍因为结账过程繁琐常常很长,但面包种类少、外形相似的特点却能够实现智能识别。所以我认为可以运用智能识别与扫码相结合的方式,实现面包店自主称重结账,使结账更便捷。
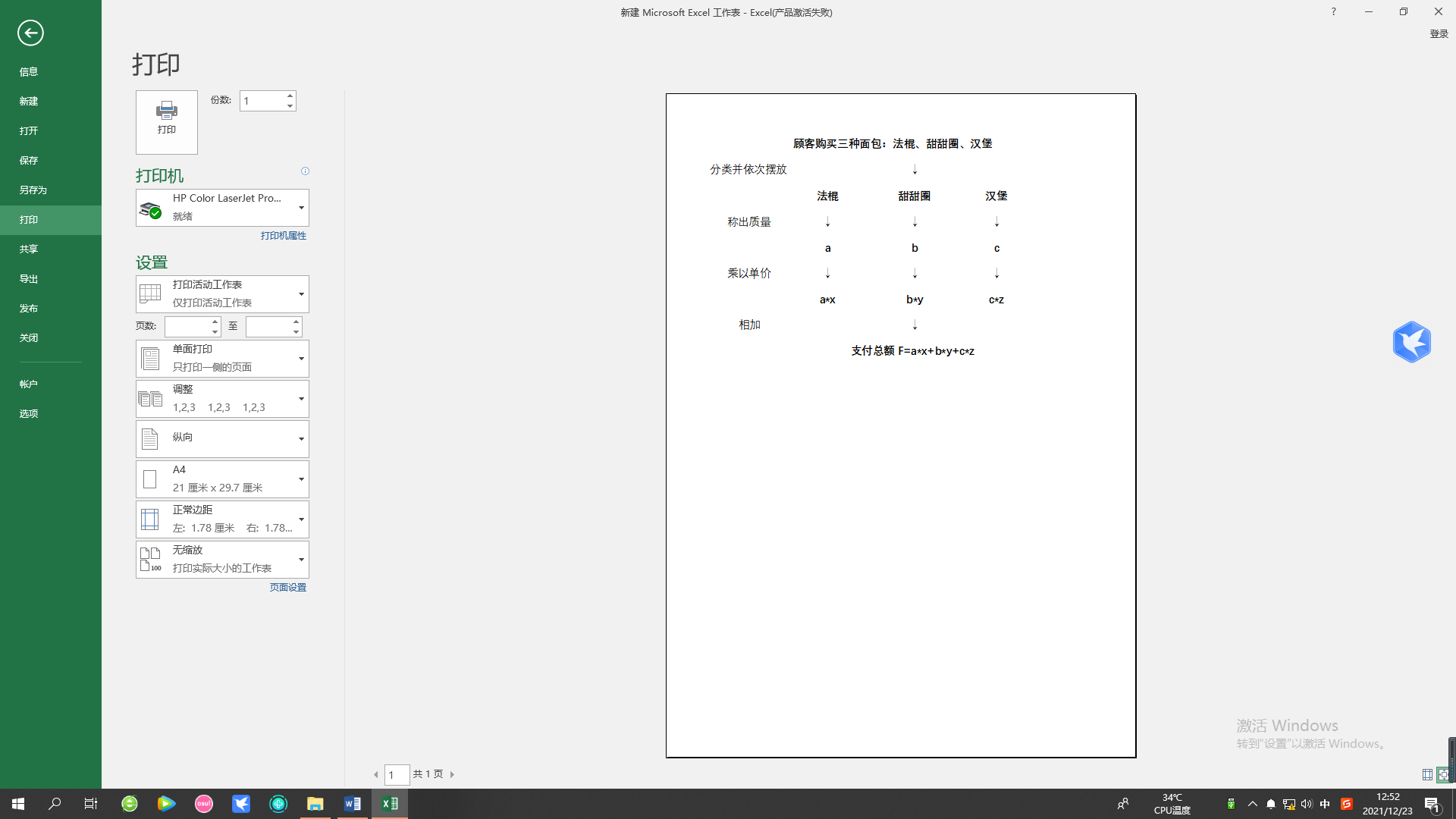
例如:一位顾客购买了三根法棍、两个甜甜圈及一个汉堡进进行分别称重。由于三根法棍属于一种面包,所以只需将所有法棍放上压力测试仪,测得法棍的真实质量a,再与每千克单价x相乘,算得法棍的价格a*x,以此类推,依次算得三种面包的价格并相加,取得支付总额F=a*x+b*y+c*z。
我们下载了约两千张面包的图片,种类有法棍、汉堡包、可颂面包、热狗、甜甜圈、圆面包等。实际使用tensorflow的最新的高阶包装库keras,训练环境是tensorflow 2.7, keras, CUDA 11.2一台安装有3060显卡的笔记本电脑(游戏本)。神经网络的组成:由输入层,第二层卷积层(大小是16x16), 激活函数是relu
第三层池化层。第四层是卷积层大小是32x32, 第五层是池化层,第六层是卷积层大小是64x64。第7层是池化层。第8层是展平层,展平成一维数组。第9层是全连接层
因为样本数据较少,预处理时对样本进行了翻转、旋转、放大操作,进行数据增强。
经实验该模型在3060显卡的笔记本电脑上只需训练1分钟左右,就能对9个分类达到70%以上的准确度,考虑到图片是网上下载的,肉眼看上去同一目录面包的类型也不完全一致,所以这个准确率比较满意。如果用相机到面包店实拍的话,准确率估计会大大提高。
关键词:深度学习、人工智能、tensorflow、keras、图像处理
随着社会、科技的发展,手机扫码等支付方式逐渐普及,人们的社会生活更加便捷。与之相反的是,在面包店买面包的实际情况却与当下的发展并不同步。我因为喜欢吃面食,经常去面包店购买面包。但在购买面包时,我发现排队等待结账的队伍常常很长,并且每位顾客所购买的面包通常是多种类型的。此时店员就需要将每种面包分别称重再与单价相乘来取得顾客所需要支付的价格。这常常需要花费很多时间,导致顾客在收费处排起长队,有些顾客甚至因此有些不耐烦。
通过了解之前学长学姐成功的植物花卉识别程序,我认为对于面包的识别也可以实现。每一家面包店内所出售的面包种类有限,且每种面包外观差异不大,所以可以运用人工智能,通过智能识别与扫码相结合的方式,实现面包店自助称重结账,以此减少店员负担,使结账收费更加便捷,加快顾客消费速度,优化我们在面包店消费的体验。
图像识别已是十分成熟的技术,其识别精度与速度都能满足本课题需求,但将该技术应用于自动识别缴费的案例还较少。
为了解决现阶段面包店支付效率低的问题与缺陷,课题运用图像识别与目标检测作为技术基础来提供解决方案。通过智能识别与扫码相结合的方式,实现面包店自助称重结账,以此减少店员负担,加快顾客消费速度。
本课题计划研究一套关于“面包所属品种”的检测系统。当我们输入一张所购买的面包的照片时,系统能准确判断面包品种并显示其零售价。
在于跟老师交流思路后,我们决定用树莓电脑、摄像头以及压力测试仪三个仪器进行简单的模型搭建。将树莓电脑与摄像头以及压力测试仪相连,首先通过摄像头将面包拍摄图像传到电脑中,经过Python编写的程序识别出面包的种类,并获得这种面包的零售价,使之与压力测试仪上称出的重量相乘,从而显示出顾客需要支付的价格,再通过二维码识别,使顾客完成自主结账。
例如:一位顾客购买了三根法棍、两个甜甜圈及一个汉堡进进行分别称重。由于三根法棍属于一种面包,所以只需将所有法棍放上压力测试仪,测得法棍的真实质量a,再与每千克单价x相乘,算得法棍的价格a*x,以此类推,依次算得三种面包的价格并相加,取得支付总额F=a*x+b*y+c*z。
我们从网上下载了共十种不同种类面包的大量照片,
汉堡包图片
因为网上下载的面包图片大小不一,格式不一,用光影魔术手统一批量处理成600x600大小的jpg图像。
3.1.1 CNN卷积运算介绍
卷积运算(Convolution)是信号处理和图像处理领域中的重要知识,更是当前DL算法中最核心的组件之一。
CV(Cornpuer Vision,计算机数学)的任务是对图像进行high-level的理解。给CV算法一张图,通过算法就可以识别出这张图中包含的因素。
我们实际使用tensorflow的最新的高阶包装的库keras,训练环境是tensorflow 2.7, 一台安装有3060显卡的笔记本电脑。
先定义batch_size为32,就是一次给神经网络的训练图片数目,图片大小同一缩减为180x180.
batch_size = 32 img_height = 180 img_width = 180
我们把原始数据分成80%的训练数据和20%的验证数据,在keras里很容易用一个函数实现,而无需手工去分目录。
train_ds = tf.keras.utils.image_dataset_from_directory( data_dir, validation_split=0.2, subset="training", seed=123, image_size=(img_height, img_width), batch_size=batch_size)
分类名由keras自动从目录结构中获取
class_names = train_ds.class_names print(class_names)
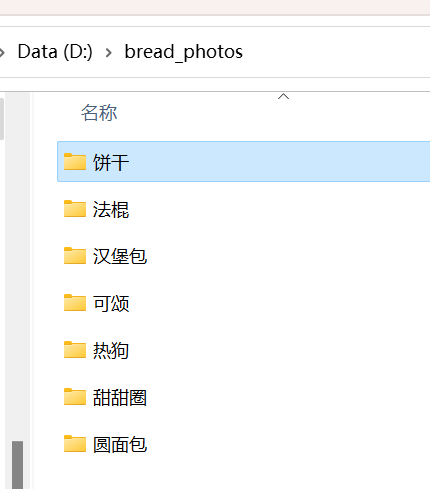
分别对应“饼干”,“法棍”,“汉堡包”“甜甜圈”,“小圆面包”,“可颂”,“圆面包”,“热狗”
for image_batch, labels_batch in train_ds: print(image_batch.shape) print(labels_batch.shape) break
这段代码打印一个批次的训练数据块大小结果为(32,180,180,3),也就是每批次传入32张图片,每张图片是180x180大小,RGB三色组成,所以最后一个是3。
最新版的tensorflow 2.x 和keras,训练时运行速度大大加快了主要用到了存储预取技术,能克服I/O的阻塞瓶颈。具体代码如下:
AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
图片RGB的通道是的数值是0-255, 对神经网络来说不是很理想,我们把数据归一化为0,1之间的数。我们用到如下语句
normalization_layer = layers.Rescaling(1./255)
我们把这个层用Dataset.map函数输入神经网络
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y)) image_batch, labels_batch = next(iter(normalized_ds)) first_image = image_batch[0] # Notice the pixel values are now in `[0,1]`. print(np.min(first_image), np.max(first_image))
接下来就是创建训练模型,用到的是keras的sequential模型,
num_classes = len(class_names) model = Sequential([ layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)), layers.Conv2D(16, 3, padding='same', activation='relu'), layers.MaxPooling2D(), layers.Conv2D(32, 3, padding='same', activation='relu'), layers.MaxPooling2D(), layers.Conv2D(64, 3, padding='same', activation='relu'), layers.MaxPooling2D(), layers.Flatten(), layers.Dense(128, activation='relu'), layers.Dense(num_classes) ])
其中num_classes在我们这里是面包种类,layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),是输入层,大小是180x180, 3个通道,然后归一化。
第二层是卷积层,大小是16x16, 激活函数是relu
第三层是池化层。池化层的作用是特征降维。就是把需要的特征突显,不需要的特征忽略。第四层也是卷积层大小是32x32, 第五层是池化层,第六层是卷积层大小是64x64。第7层是池化层。第8层是展平层,展平成一维数组。第9层是全连接层,神经元个数是128个,激活函数是relu。最后一层是全连接层,神经元个数是面包种类也就是6个。
接下来是编译模型,优化器选用adam, 神经网络的学习的目的是找到使损失函数的值尽可能小的参数,最早用的是SGD(随机梯度下降法),Adam是2015年才提出的新方法,有望实现参数空间的高效搜索。搭建深度学习模型,构建损失函数经常用到交叉熵函数,同时用到SparseCategoricalCrossentropy。
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
该accuracy就是大家熟知的最朴素的accuracy。比如我们有6个样本,其真实标签y_true为[0, 1, 3, 3, 4, 2],但被一个模型预测为了[0, 1, 3, 4, 4, 4],即y_pred=[0, 1, 3, 4, 4, 4],那么该模型的accuracy=4/6=66.67% 由于样本数据较小,我们采取图像增强措施,
data_augmentation = keras.Sequential( [ layers.RandomFlip("horizontal", input_shape=(img_height, img_width, 3)), layers.RandomRotation(0.1), layers.RandomZoom(0.1), ] )
随机在水平方向翻转,随机旋转,随机缩放。layers.RandomRotation(0.1),其中这里的0.1,factor=0.1相当于在-36度到+36度之间旋转 [-10% * 2pi, 10% * 2pi]
layers.RandomZoom(0.1),相当于高度放大10%
同样因为样本数据较小,减小过拟合的layers.Dropout(0.2),意味着在训练过程中随机扔掉20%的数据,然后对模型进行编译,和训练,因为收敛较快,这里只训练30次。用时1分钟不到。以下是部分代码。
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
epochs = 30
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
训练截图:
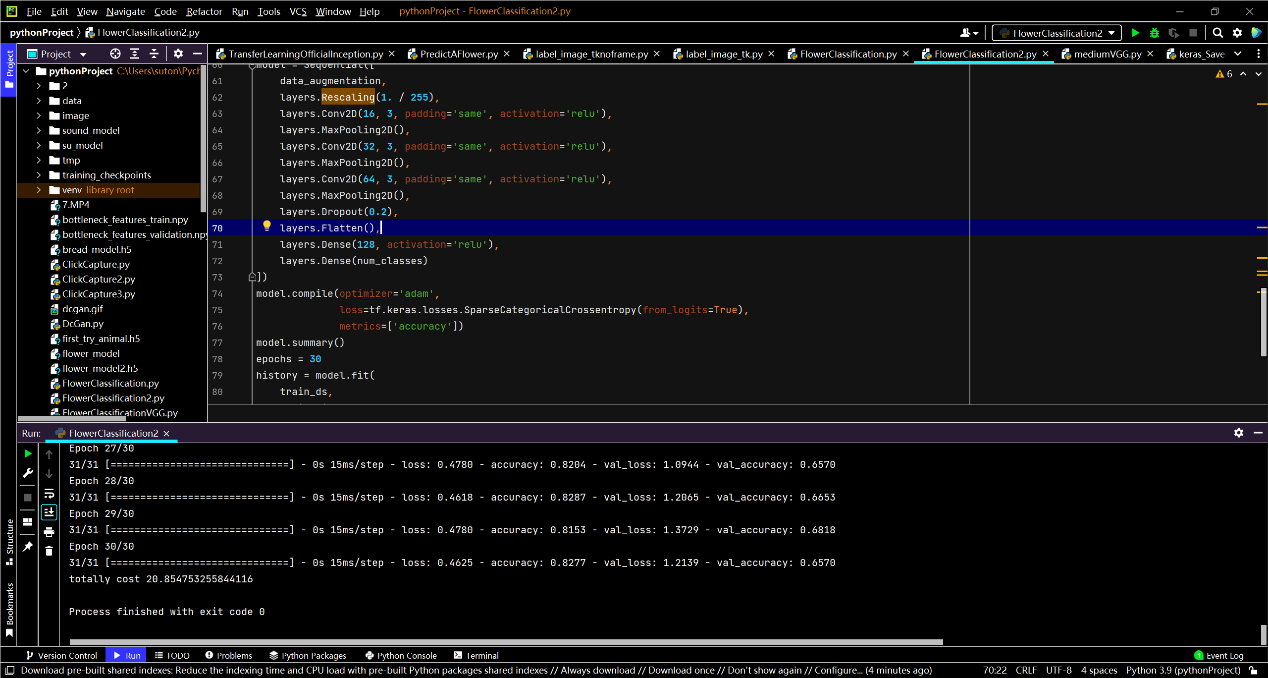
这次的准确率68%
把训练模型保存成bread_model.h5,
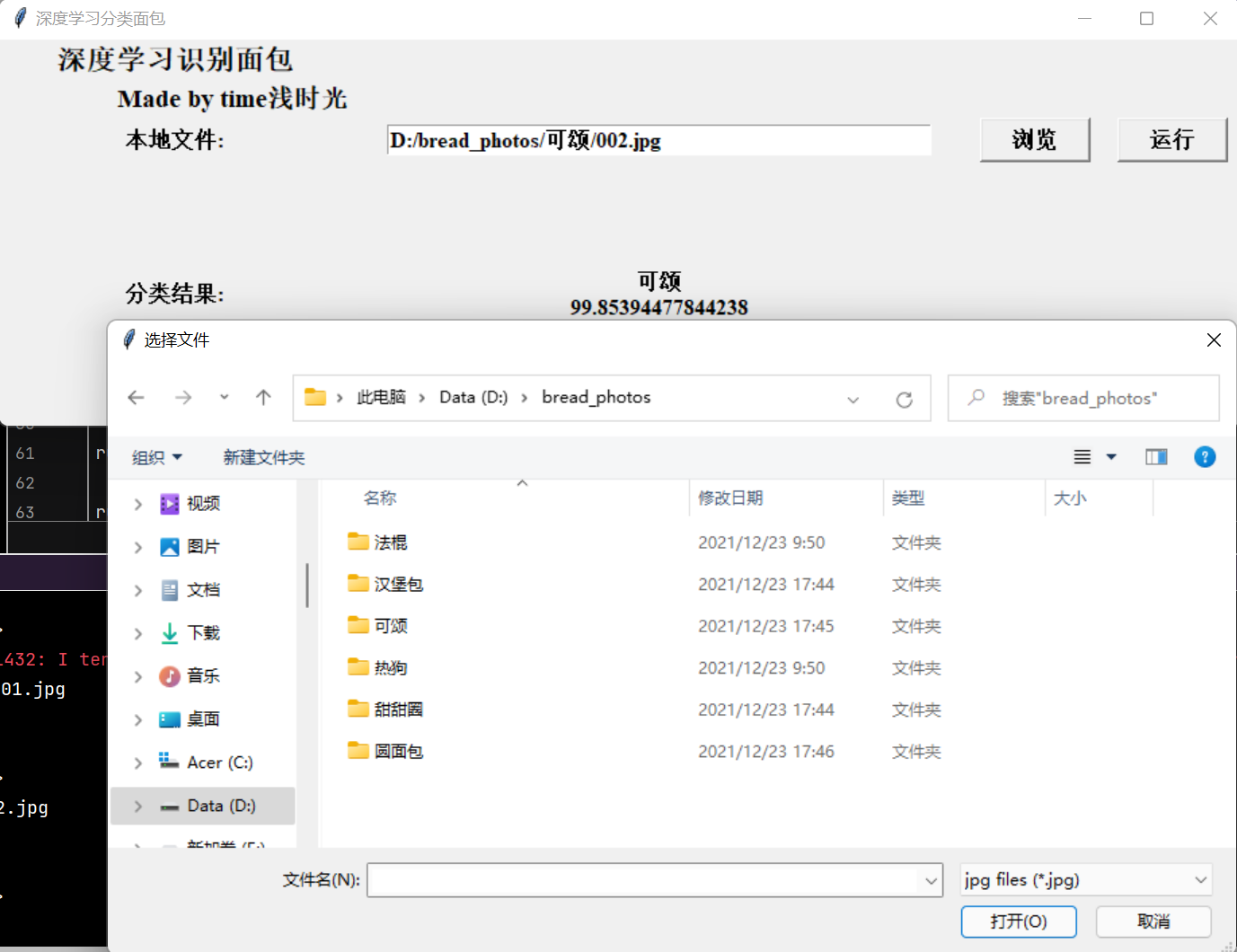
第四章,编写图形界面选择任意一个图像(面包)文件进行验证
编写一个程序可以对任意文件夹内的面包图形界面采用python的tkinter库,图片选择如下图:
运行结果:
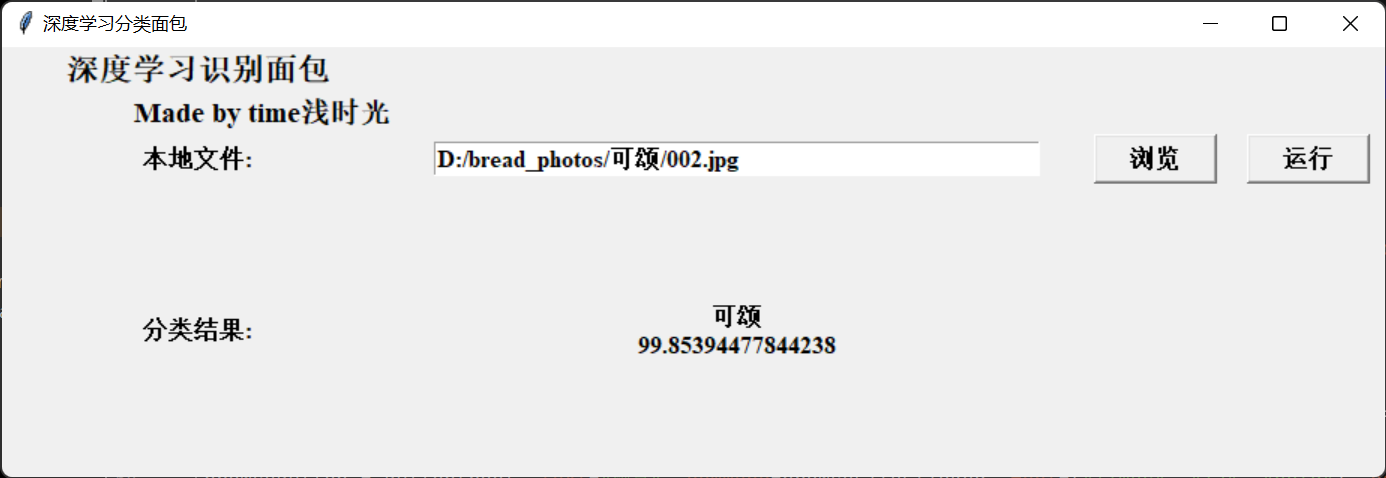
对这张图片的分类结果是“可颂面包”置信度达到99%。
图形显示部分文件选择框部分代码:
def browseFileClicked(): global file_name file_name = filedialog.askopenfilename(initialdir="d:/flower_sixphotos", title="选择文件", filetypes=(("jpg files", "*.jpg"), ("all files", "*.*"))) valueFilename.set(file_name) print(file_name)
以下是加载模型部分代码
def runClicked(file_name):
global valueResults
try:
img = tf.keras.utils.load_img(
file_name, target_size=(img_height, img_width)
)
img_array = tf.keras.utils.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
reconstructed_model = tf.keras.models.load_model('flower_model2.h5')
predictions = reconstructed_model.predict(img_array)
result = CLASS_NAMES[predictions.argmax(axis=1)[0]]
score = tf.nn.softmax(predictions[0])
confidence = 100*np.max(score)
参考文献
| [1]杜泽桉. 利用Keras高级神经网络实现商品销量的预测[J]. 电子制作,2019(Z1):76-79. |
| [2]郑洋洋,白艳萍,侯宇超. 基于Keras的LSTM模型在空气质量指数预测的应用[J]. 数学的实践与认识,2019,49(07):138-143. |
| [3]杨梦卓,郭梦洁,方亮. 基于keras的卷积神经网络的图像分类算法研究[J]. 科技风,2019(23):117-118. |
| [4]高云,彭炜. 基于Keras的分类预测应用研究[J]. 山西大同大学学报(自然科学版),2019,35(05):26-30. |
| [5]王恒涛. 基于TensorFlow、Keras与OpenCV的图像识别集成系统[J]. 电子测试,2020(24):53-54+124. |
| [6]时瑶佳,吴飞,朱海,韩学法. 基于Keras平台的LSTM模型的对流层延迟预测[J]. 全球定位系统,2020,45(06):115-122. |
| [7]张震,朱权洁,李青松,刘衍,张尔辉,赵庆民,秦续峰. 基于Keras长短时记忆网络的矿井瓦斯浓度预测研究[J]. 安全与环境工程,2021,28(01):61-67+78. |
| [8]屈晨. 基于Keras的CSI被动室内定位方法的研究[D].合肥工业大学,2020. |
| [9]方碧云. 基于Keras框架下的网络电影数据分析[J]. 电脑知识与技术,2019,15(34):14-16. |
| [10]王培雷. 基于残差网络的多标签图像检索方法研究[D].桂林电子科技大学,2019. |